
欠損値埋めや前処理を組み込んだパイプライン構築に欠かせないColumnTransformerですが、デフォルトでは指定した特徴量以外は自動でドロップされることに気を付けましょう!
トランスフォームしない特徴量も保持したい場合は引数remainderに’passthrough’を指定する必要があります!
私のケースではパイプラインを構築してからモデル学習、予測を実行した段階で、奇妙なぐらい精度が低かったことから問題が発覚しました。パイプライン化されているため問題個所がどこかわからず、ウェブ検索やChatGPTを駆使しても問題解決にたどり着くまでに時間がかかったので記事にしました。
今回の記事では以下の4点について説明していきます。
- テストデータの漏洩を防ぐために、前処理は学習データで.fit_transform、テストデータで.transformを実行する
- そのためにはColumnTransformerを組み込んだパイプライン化が必要
- 何もしない特徴量がある場合には引数remainder=’passthrough’を必ず指定する
- 構築したパイプラインは学習(.fit)後に可視化して各処理を確認する
ColumnTransformerを使ってPipelineを構築
fitメソッドが必要な前処理(StandardScaler、SimpleImputerなど)を扱う場合、学習データに.fit_transform、テストデータには.transformのみを適用する必要があります。
なぜかというと、テストデータに.fit_transformを適用すると学習データとテストデータで処理内容が均一ではなくなります。一方でデータ分割前のテストデータを含めた状態で.fit_transformを実行してしまうと正解情報が漏洩した状態で前処理を実施したことになるからです。
欠損値埋めや前処理は必ず以下の手順で実施する必要があり、パイプライン化するためにはColumnTransformerクラスを使う必要があります。
手順
- 学習データ(X_train)とテストデータ(X_test)に分割
- preprocessing_instance.imputer.fit_transform(X_train)
- preprocessing_instance.transform(X_test)
ColumnTransformerの基本的な使い方
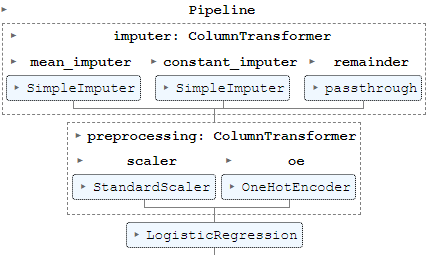
ColumnTransformerはパイプライン内で特徴量を分割させて並列処理を行う場合に使います。各処理を処理名、処理のインスタンス、処理を行う特徴量リストの3要素のタプルで定義し、さらに並列して行う各処理をリスト内に並べます(下図)。

実際のコードを見たほうが理解が早いと思いますので、例として欠損値埋めと前処理(標準化とOne-Hotエンコーディング)を組み込んだパイプラインを構築します。
# X: 特徴量のデータフレーム
# 欠損値埋めのトランスフォーマー
imputer = ColumnTransformer([
('mean_imputer', SimpleImputer(strategy='mean'), ['Age']),
('constant_imputer', SimpleImputer(strategy='constant', fill_value=np.nan), ['Cabin'])
],
remainder='passthrough')
# 前処理のトランスフォーマー
num_cols = X.select_dtypes(include=np.number).columns.tolist()
cat_cols = X.select_dtypes(exclude=np.number).columns.tolist()
preprocessing = ColumnTransformer([
('scaler', StandardScaler(), num_cols),
('oe', OneHotEncoder(), cat_cols)
])
# パイプライン化
pipeline = Pipeline([
('imputer', imputer), # ColumnTransformer 1: 欠損値埋め
('preprocessing', preprocessing), # ColumnTransformer 2: 標準化とOE
('model', LogisticRegression()) # 例としてLogisticRegression
])
このようなパイプラインを構築して交差検証(CV)を行えば、学習データで.fit_transform、テストデータには.transformのみが自動で適用されます。便利ですね!
ケース1. remainderがデフォルトで問題ないケース
ColumnTransformerで数値カラム [numerical_columns]を標準化、カテゴリカルカラム[categorical_columns]をone-hotエンコーディングを組み込んだパイプラインを構築したいケースを例に考えます。
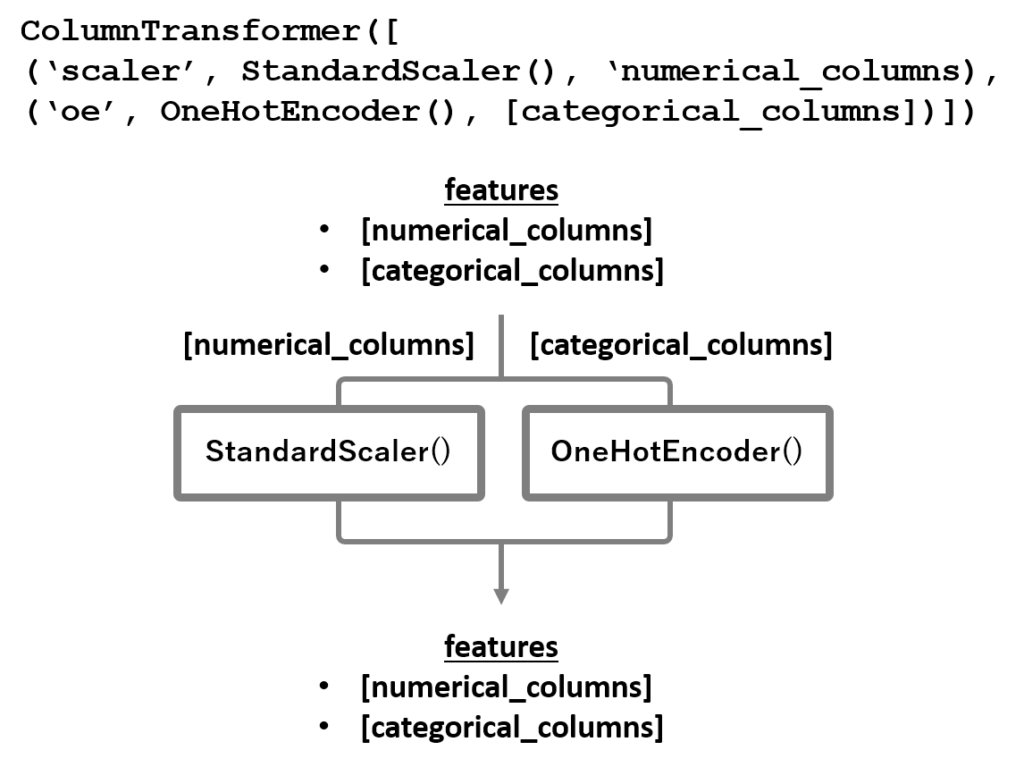
この場合は全特徴量が数値カラムとカテゴリカラムに分岐してそれぞれの前処理が適用された後に合流するため、ColumnTransformerはデフォルト設定で問題ありません。
コードとしては以下のようになります。
# X: 特徴量のデータフレーム
# y: 正解ラベル
num_cols = X.select_dtypes(include=np.number).columns.tolist()
cat_cols = X.select_dtypes(exclude=np.number).columns.tolist()
# ColumnTransformerに各カラムに対する処理を指定
ct = ColumnTransformer([ # 特徴量ごとに分けて処理する内容のリスト
('scaler', StandardScaler(), num_cols), # 数値カラムに標準化
('oe', OneHotEncoder(), cat_cols) # カテゴリカルカラムをOne-Hotエンコーディング
])
# ColumnTransformerを含めたパイプライン構築
pipeline = Pipeline([
('ct', ct), # ColumnTransformer
('model', LogisticRegression()) # 例としてLogisticRegression
])
# KFold
cv = KFold(n_splits=5, shuffle=True, random_state=0)
results = cross_validate(pipeline, X, y, cv=cv)ケース2. remainder=’passthrough’ではないと問題あるケース
カテゴリカルカラムだけにone-hotエンコーディングを行うケースを想定します。この場合は数値カラムには何もしないのですが、だからといって放置するとデフォルトでは処理を指定したカラム以外はドロップされてしまいます(下図左)。ここでColumnTransformerの引数remainder=’passthrough’と設定すると、指定しなかったカラムも保持することができます(上図右)。
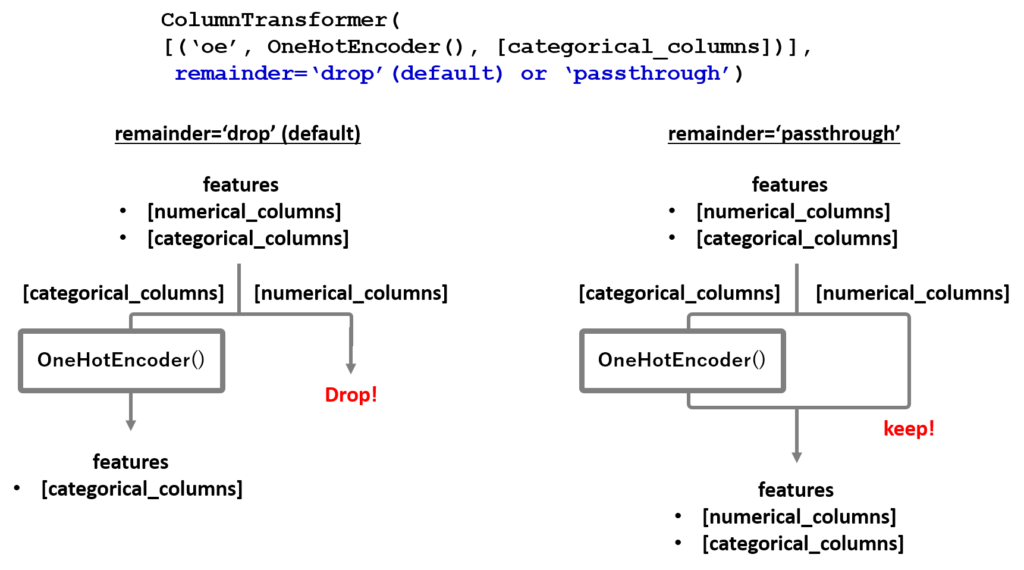
以下に具体的なコードを記載します。引数remainderにpassthroughを指定するだけで解決します!
cat_cols = X.select_dtypes(exclude=np.number).columns.tolist()
# カテゴリカルカラムに対する処理を指定
ct = ColumnTransformer([('oe', OneHotEncoder(), cat_cols)], # 特徴量ごとに分けて処理する内容のリスト
remainder='passthrough') # 指定しなかったカラムを保持
pipeline = Pipeline([
('ct', ct), # ColumnTransformer
('model', LogisticRegression()) # 例としてLogisticRegression
])
# cv
cv = KFold(n_splits=5)
results = cross_validate(pipeline, X, y, cv=cv)特徴量の行方を確認する方法
一度パイプラインを組んでしまうと個々の処理のアウトプットを確認できないためにエラー原因を突き止めにくいのですが、ColumnTransformerで分岐して処理されている特徴量はpipeline.fit(X, y)でセルを実行すると確認できます。
.fitでJupyterのセルを実行するとパイプラインの全体像を可視化してくれます。そしてトランスフォーマーの処理を展開すると、どのカラムに処理が適用されているか確認できます。
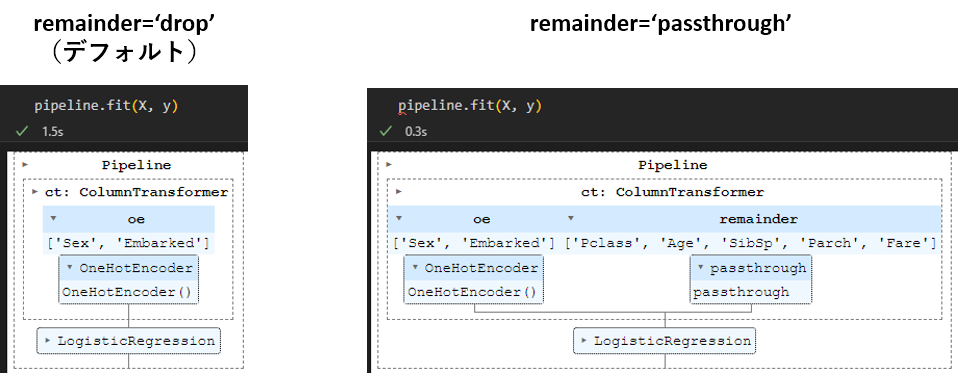
デフォルトではカテゴリカルカラムだけが処理されてロジスティック回帰に渡されています。一方でpassthroughを指定すれば数値カラムには「何もしない」処理が(passthrough)が適用された後、ColumnTransformerのあとで合流します。
まとめ
以上がColumnTransformerの使い方と引数remainderの注意点となります。指定したカラムだけに欠損値埋め(SimpleImputer、KNNImputerなど)を適用する場合にもpassthrough設定は必要になるので、忘れないようにしましょう!
passthrough設定せずにKFoldでハイパーパラメータチューニングなど時間がかかる処理を実行すると、時間だけ浪費して意味不明な結果に翻弄されるという残念な事態になります・・・(自分だけ?)
皆さんもColumnTransformerの引数remainderの存在を忘れないようにしましょう!


コメント